
Projects
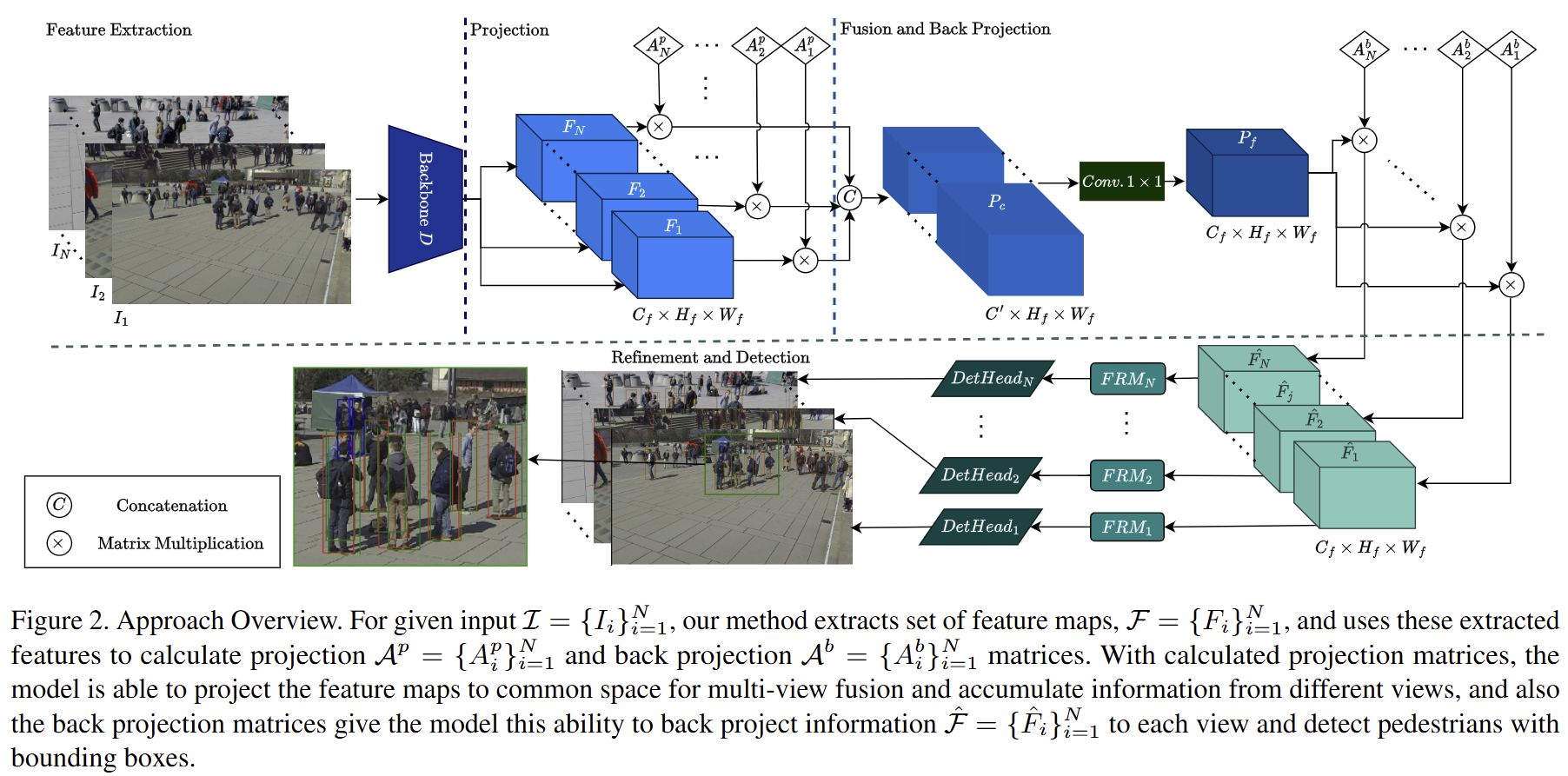
CaMuViD: Calibration-Free Multi-View Detection
Multi-view object detection in crowded environments presents significant challenges, particularly for occlusion management across multiple camera views. This project introduces a novel approach that extends conventional multi-view detection to operate directly within each camera's image space. Our method finds objects bounding boxes for images from various perspectives without resorting to a bird’s eye view (BEV) representation. Thus, our approach removes the need for camera calibration by leveraging a learnable architecture that facilitates flexible transformations and improves feature fusion across perspectives to increase detection accuracy. We used Python and PyTorch for implementation.
Learn More
A Real-Time System for Correlating Belongings with Passengers Towards Real Airport
Our research group is proud to contribute to the CLASP (Correlating Luggage and Specific Passengers) project, which is funded by the U.S. Department of Homeland Security Science and Technology Directorate through ALERT. This initiative aims to enhance security at checkpoints by utilizing advanced video analytics to automatically track passengers and their belongings. This project's implementation was based on Python and PyTorch.
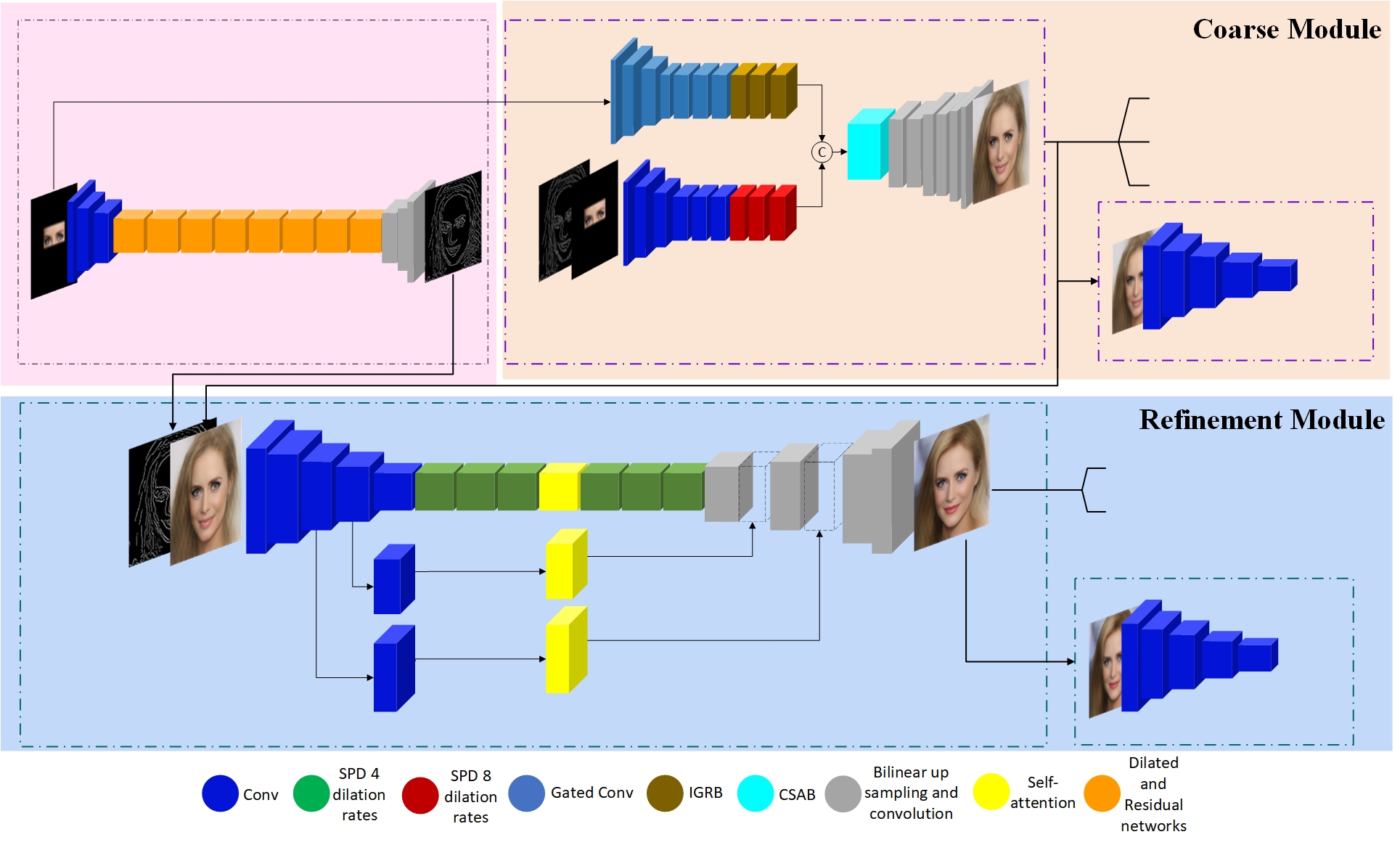
E2F-GAN: Eyes-to-Face Inpainting via Edge-Aware Coarse-to-Fine GANs
Face inpainting is a challenging task aiming to fill the damaged or masked regions in face images with plausibly synthesized contents. Based on the given information, the reconstructed regions should look realistic and more importantly preserve the demographic and biometric properties of the individual. The aim of this project was to reconstruct the face based on the periocular region (eyes-to-face). This project's implementation was based on Python and Tensorlfow.
Learn More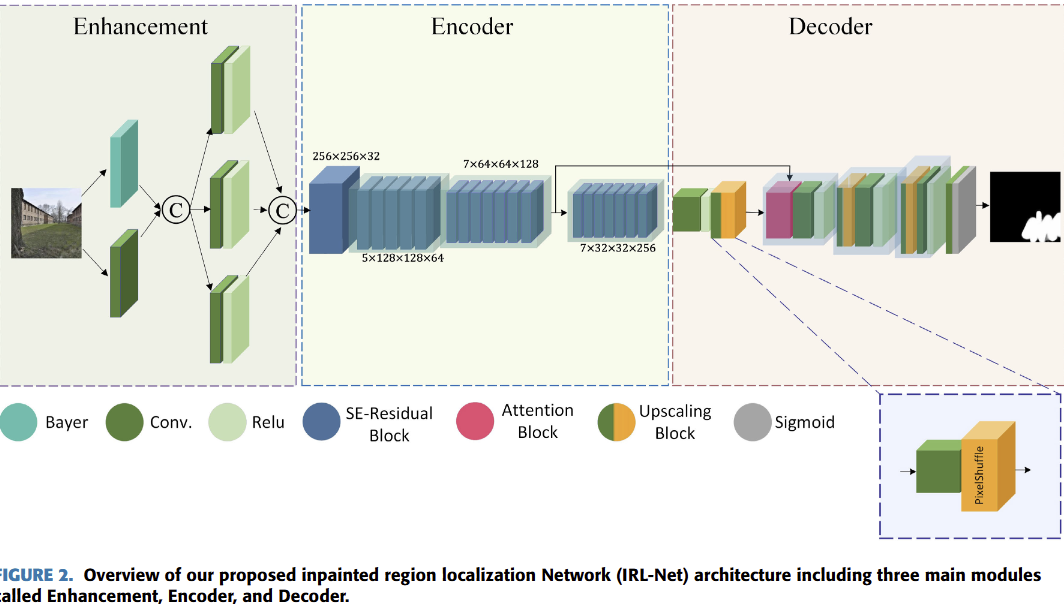
IRL-Net: Inpainted Region Localization Network via Spatial Attention
Identifying manipulated regions in images is a challenging task due to the existence of very accurate image inpainting techniques leaving almost unnoticeable traces in tampered regions. These image inpainting methods can be used for multiple purposes (e.g., removing objects, reconstructing corrupted areas, eliminating various types of distortion, etc.) makes creating forensic detectors for image manipulation an extremely difficult and time-consuming procedure. The aim of this project was to localize the tampered regions manipulated by image inpainting methods. This project's implementation was based on Python and Tensorlfow.
Learn More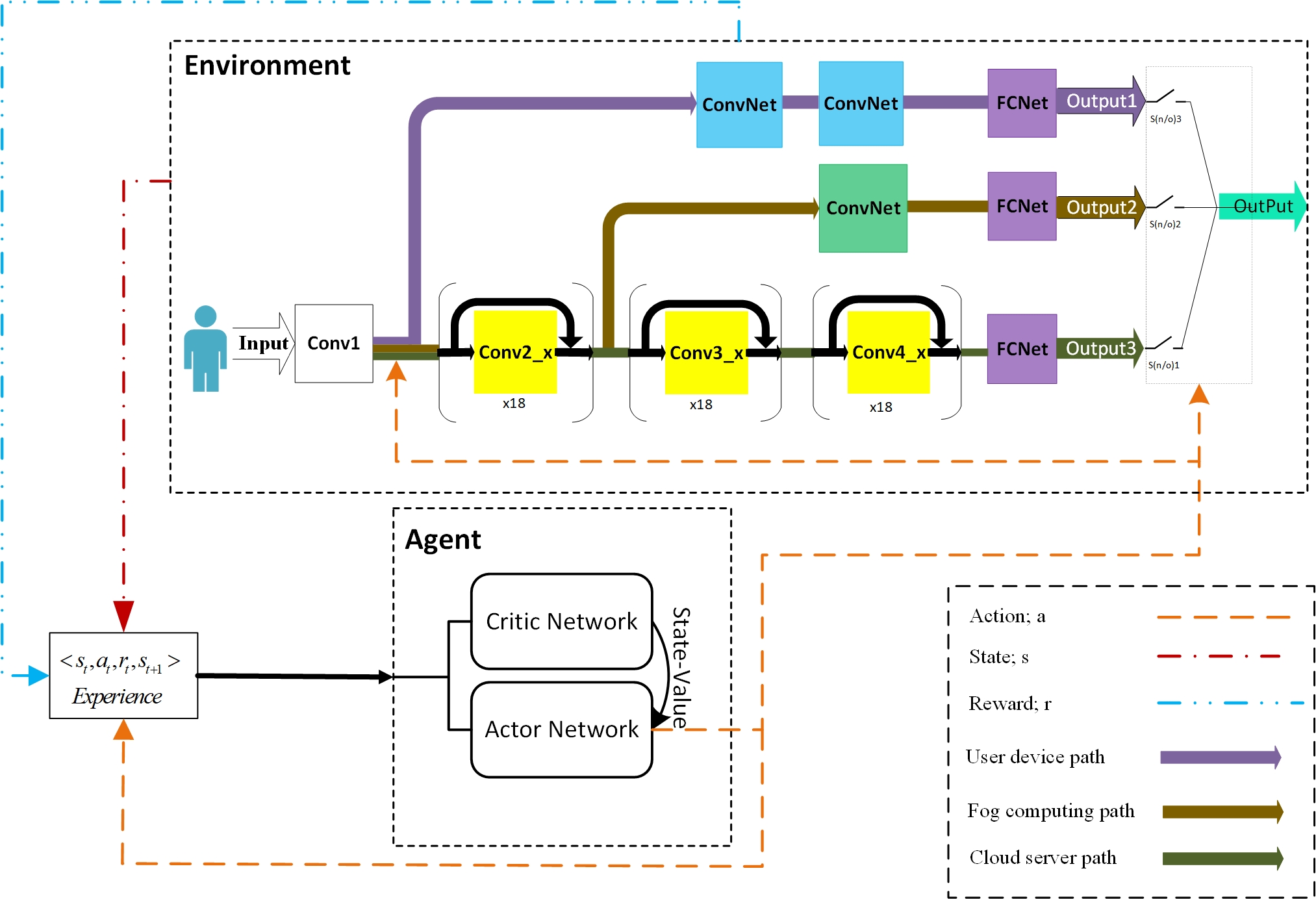
IRL-Net: Inpainted Region Localization Network via Spatial Attention
The increasing expansion of Internet-of-Things (IoT) in the world requires Big Data analytic infrastructures to produce valuable knowledge in IoT applications. IoT includes devices with limited resources, whereby it requires efficient platforms to process massive data obtained from sensors. Nowadays, many IoT applications such as audio and video recognition depend on state-of-the-art Deep Neural Networks (DNNs). Therefore, we need to execute DNNs on IoT devices. DNNs offer excellent recognition accuracy but they suffer from high computational and memory resource demands. Due to these constraints, currently, IoT applications that depend on deep learning are mostly offloaded to cloudlets and clouds. Offloading imposes extra network bandwidth consumption costs in addition to delayed response for IoT devices. In this project, we propose a method that instead of using all layers of DNN for inference, only selects a subset of layers that provide sufficient accuracy for each task. This project's implementation was based on Python and Tensorlfow.
Learn More